コンピューターにテキストを音声に変換させると、人間の声とは異なる、周波数の微妙な揺らぎを感じるはずだ。グーグルの機械学習系子会社ディープマインドは、人工知能による音声合成の新システムを開発し、この問題を解決しようとしている。
コンピューターに発話させるのは新しい試みではない。最も一般的なアプローチは、ある人の膨大な数の録音から採取した音の断片をつなぎ合わせることだろう。「素片接続型」と呼ばれる手法では、音の断片をつなげて音節や単語、文を合成する。だが、コンピューター出力の発話にはノイズやイントネーションの不自然な変化、発音のばらつきなどの問題がある。一方で、「パラメトリック音声合成」と呼ばれる手法では、数学的モデルで再現した既定の音節から単語や文を組み立てる。不具合を起こしにくい反面、いかにもロボットな音声になってしまうのが欠点だ。
2つの手法の共通点は、音声波形全体を生成するのではなく、音節をつなぎ合わせていることだ。

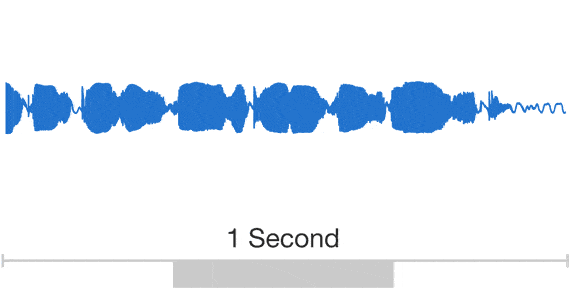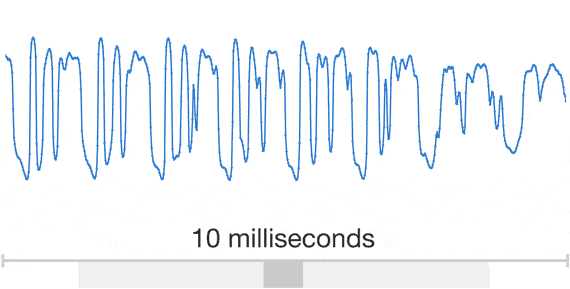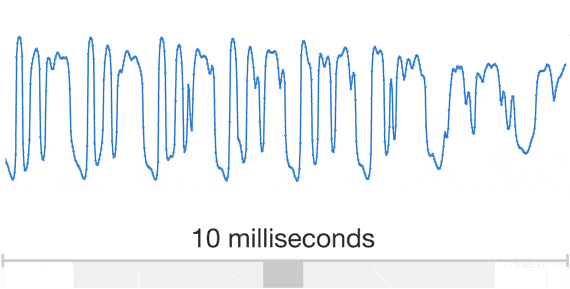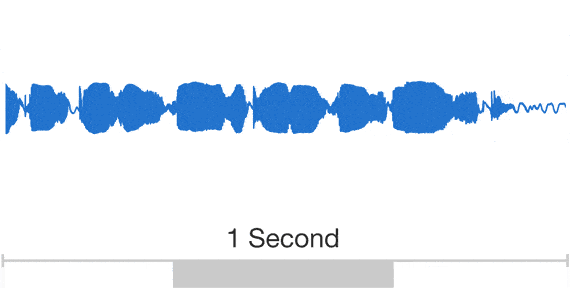
ところが、ディープマインドの手法では、音声波形全体を生成する。「WaveNet」(ディープマインドの音声生成モデル)の畳み込みニューラルネットワークは、本物の人間の音声の断片と、対応する言語学的、音声学的な特徴を与えることで、2つに関連するパターンを識別できるように訓練される。音声を出力するとき、WaveNetには音声の特徴をテキストから生成した与え、テキストから再生されるべき音の波形全体を未加工の状態で作り出す。最初のサンプルを作り、既存のサンプルの情報を参照して次のサンプルを生成する処理を繰り返すことで、音波を完成させる仕組みだ。
研究成果は、十分納得のいく聞き心地だ。素片接続型やパラメトリック音声合成に比べて、はるかに人間的な音声だ。
ただし、難点がある。この手法は膨大な計算量が必要で、波形全体の生成に、WaveNetは毎秒1万6000ものサンプルを作るため、ニューラルネットワークのプロセスを使わなくてはいけない(しかも合成音声の品質はせいぜい電話かVoIPと同レベルだ)。ファイナンシャルタイムズ紙(有料会員のみの記事)によると、ディープマインドの話では現在のところ、WaveNetがグーグル製品に採用される計画はない。
もちろん、不自然な発話は、コンピューターが直面する言語上の唯一の問題ではない。音声や言葉の解釈も、人工知能システムには異常なほど難しい。少なくともこの調子でいけば、コンピューターが真の知性を獲得するための手段をすべて得たとき、コンピューターは得意げにできるようになったことを人間に教えてくれることだろう。
(関連記事:DeepMind, Financial Times, “AI’s Language Problem”)