グーグル、短い「音」から続きを生成するオーディオAI
グーグルの新しい技術「オーディオLM(AudioLM)」は、人間が準備したテキストやラベル付けをした訓練データなしに、これまで以上に自然なオーディオを生成する。 by Tammy Xu2022.10.14
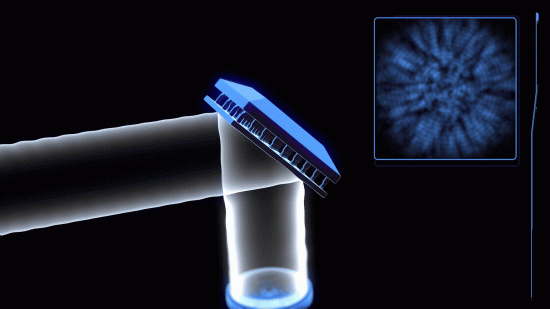
グーグルの研究チームが開発した新しい人工知能(AI)システムは、数秒間の録音データを与えるだけで、それに続く自然なスピーチや音楽を作ることができる。
「オーディオLM(AudioLM)」は、ピアノ曲のような複雑な音や人間の音声など、プロンプトのスタイルに合ったオーディオを、元の録音データとほとんど遜色ないレベルで生成する技術だ。オーディオ生成AIの訓練プロセスを高速化する可能性がある技術であり、いずれは映像に乗せて流す音楽の自動生成にもつながるかもしれない。
自然言語処理を利用した音声アシスタントのアレクサ(Alexa)に代表されるように、AIによって生成されたオーディオはすでに一般化している。オープンAI(OpenAI)の「ジュークボックス(Jukebox)」のようなAI音楽システムは、見事な結果を出している。だが、多くの既存の技術は、人間が文字起こしを準備したりテキストベースの訓練データにラベル付けをしたりする必要があるため、非常に多くの時間と労力がかかる。例えば、ジュークボックスではテキストベースのデータを使って歌詞を生成している。
9月に発表された非査読論文で説明されたオーディオLMは、多くの既存の技術とは異なり、文字起こしもラベル付けも不要だ。その代わり、音データベースをプログラムに読み込み、機械学習で録音ファイルを「トークン」と呼ばれる音の断片に、さほど情報を失うことなく圧縮する。そして、トークン化された訓練データを、自然言語処理を使って音のパターンを学習する機械学習モデルに読み込ませる。
オーディオを生成するには、数秒間の録音データを与えるだけでいい。オーディオLMはそれに続く音を予測する。GPT-3のような言語モデルが、次につながる文章や単語を予測するのと似たプロセスだ。
研究 …
- 人気の記事ランキング
-
- Trajectory of U35 Innovators: Akito Noiri 野入亮人:シリコン量子ビットで大規模化の壁に挑む研究者
- Promotion Call for entries for Innovators Under 35 Japan 2026 「Innovators Under 35 Japan」2026年度候補者募集のお知らせ
- PsiQuantum has a plan to make a massive quantum computer out of light 光に賭けたサイクオンタム、 100万量子ビット達成へ 「大胆な約束」は果たせるか
- Why heat pumps are still so hot in the US 税額控除終了後も売れ行き好調、米国ヒートポンプ市場の底堅さ
- Anthropic found a hidden space where Claude puzzles over concepts LLMは何を考えているのか? アンソロピックが見つけた「隠れた領域」