フラッシュ2022年5月17日
-
東工大、ビジョン・トランスフォーマーをレンズレスカメラに応用
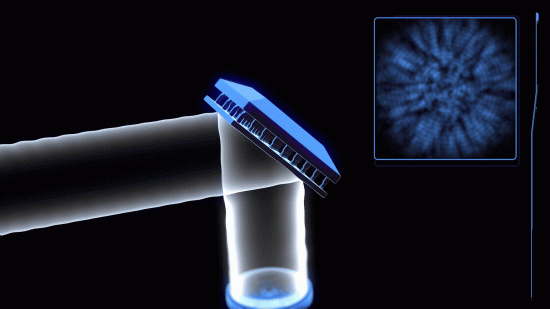
by MITテクノロジーレビュー編集部 [MIT Technology Review Japan]東京工業大学の研究チームは、グーグルの画像処理モデル「ビジョン・トランスフォーマー(ViT)」を利用したレンズレスカメラの画像再構成処理を開発した。コンピューターによる画像再構成処理を応用することで、レンズを使用せずに画像を得る「レンズレスカメラ」が注目されているが、画質が不十分で計算時間がかかるなど実用面での制約があった。新手法によって、超薄型で軽量かつ低コストなレンズレスカメラの実用性が高まりそうだ。
レンズレスカメラの画像再構成の技術としては、モデルに基づく復号法と、機械学習を用いた手法が研究されてきたが、前者は画像品質が低下しやすく、後者はレンズレス光学系の特性に適していないという問題があった。そこで研究チームは、機械学習アルゴリズムの中でも2020年にグーグルが発表したビジョン・トランスフォーマーを採用。従来の機械学習を用いた復号手法では画像内の局所的関係を主に学習していたのに対して、ViTは画像内の大局的な特徴量を利用するため、イメージセンサーの広い範囲にわたる投影パターンの処理に適しているという。
新手法を利用したレンズレスカメラは、従来の手法を用いたものよりもノイズが少なく鮮明な画像を生成できた。さらに計算時間が短く、リアルタイム撮影にも対応可能だという。
研究成果は3月31日、「オプティクス・レターズ(Optics Letters)」誌に掲載された。
(笹田)
-
- 人気の記事ランキング
-
- Trajectory of U35 Innovators: Akito Noiri 野入亮人:シリコン量子ビットで大規模化の壁に挑む研究者
- Promotion Call for entries for Innovators Under 35 Japan 2026 「Innovators Under 35 Japan」2026年度候補者募集のお知らせ
- Anthropic found a hidden space where Claude puzzles over concepts LLMは何を考えているのか? アンソロピックが見つけた「隠れた領域」
- What Anthropic’s latest AI discovery does—and doesn’t—show Claudeの「頭の中」は本当に見えたのか、AI担当編集者に聞く
- Why heat pumps are still so hot in the US 税額控除終了後も売れ行き好調、米国ヒートポンプ市場の底堅さ