医用画像の大規模データセットをAIで自動生成、エヌビディアなど
米国の研究チームが、医療用人工知能(AI)を訓練するために、さらに大規模かつ多様なデータセットを作り出すシステムを構築した。
AIの有効性は訓練に使われるデータセットの持つ有効性に左右される。ほとんどのAIプログラムにとって、学習に用いる大量の情報が有効性の拠り所となっているからだ。データが全人口や全環境を表すものではない場合、AIが偏りのあるものとなったり、役に立たないものになったりする可能性がある。
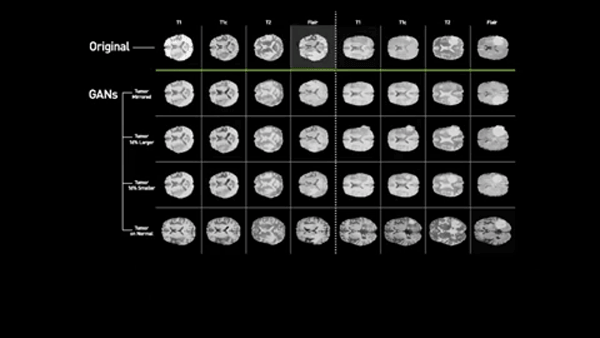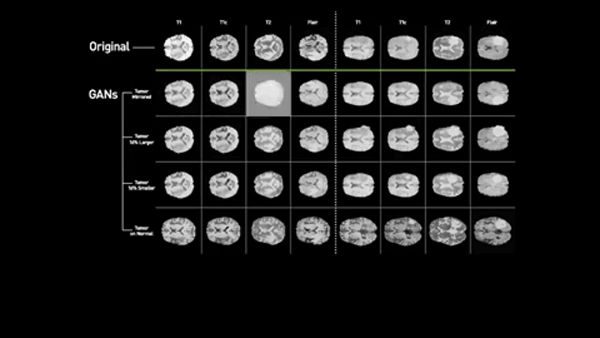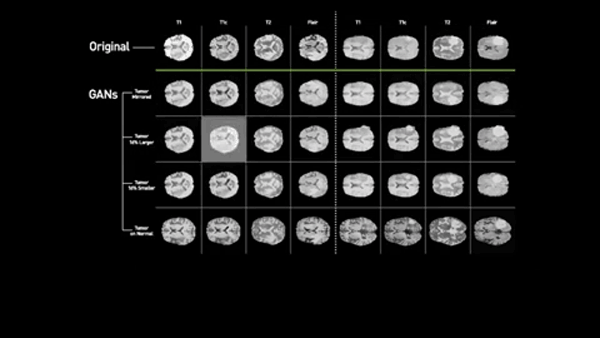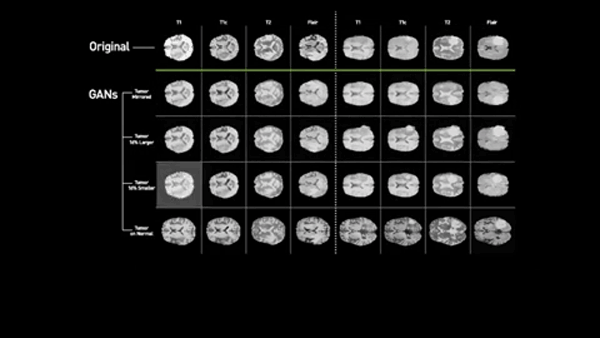
半導体メーカーのエヌビディア(Nvidia)、メイヨー・クリニック(Mayo Clinic)、MGH&BWH臨床データ科学センター(MGH and BWH Center for Clinical Data Science)による新たな研究では、多様性に優れた医療データセットを出力するアルゴリズムが作成された。競争式生成ネットワーク(GAN)を使い、 既存の脳腫瘍のMRIを基にして異常な状態を示すスキャン画像を合成できるようになったのだ。
「ニューラル・ネットワークの訓練を成功させるには、データの多様性が極めて重要ですが、たいていの場合、医用画像データには偏りがあります」と、ジーディーネット(ZDNet)に語るのは、エヌビディアの研究者のフー・チャン・シンだ。「疾患を検知し、診断するために必要なのは異常な事例の方ですが、異常な事例よりも正常な事例の方がはるかに多いのです」。
- 参照元: ZDNET
 オープンAIが「年齢予測」導入、子ども保護の責任誰が負う?
オープンAIが「年齢予測」導入、子ども保護の責任誰が負う?
 eムック 『新・陰謀論の時代 社会を蝕む「信念」の正体』特集号
eムック 『新・陰謀論の時代 社会を蝕む「信念」の正体』特集号 期待外れのCRISPR治療、包括的承認で普及目指す新興企業
期待外れのCRISPR治療、包括的承認で普及目指す新興企業 書評:サム・アルトマンはいかにして「AI帝国」を築いたか
書評:サム・アルトマンはいかにして「AI帝国」を築いたか