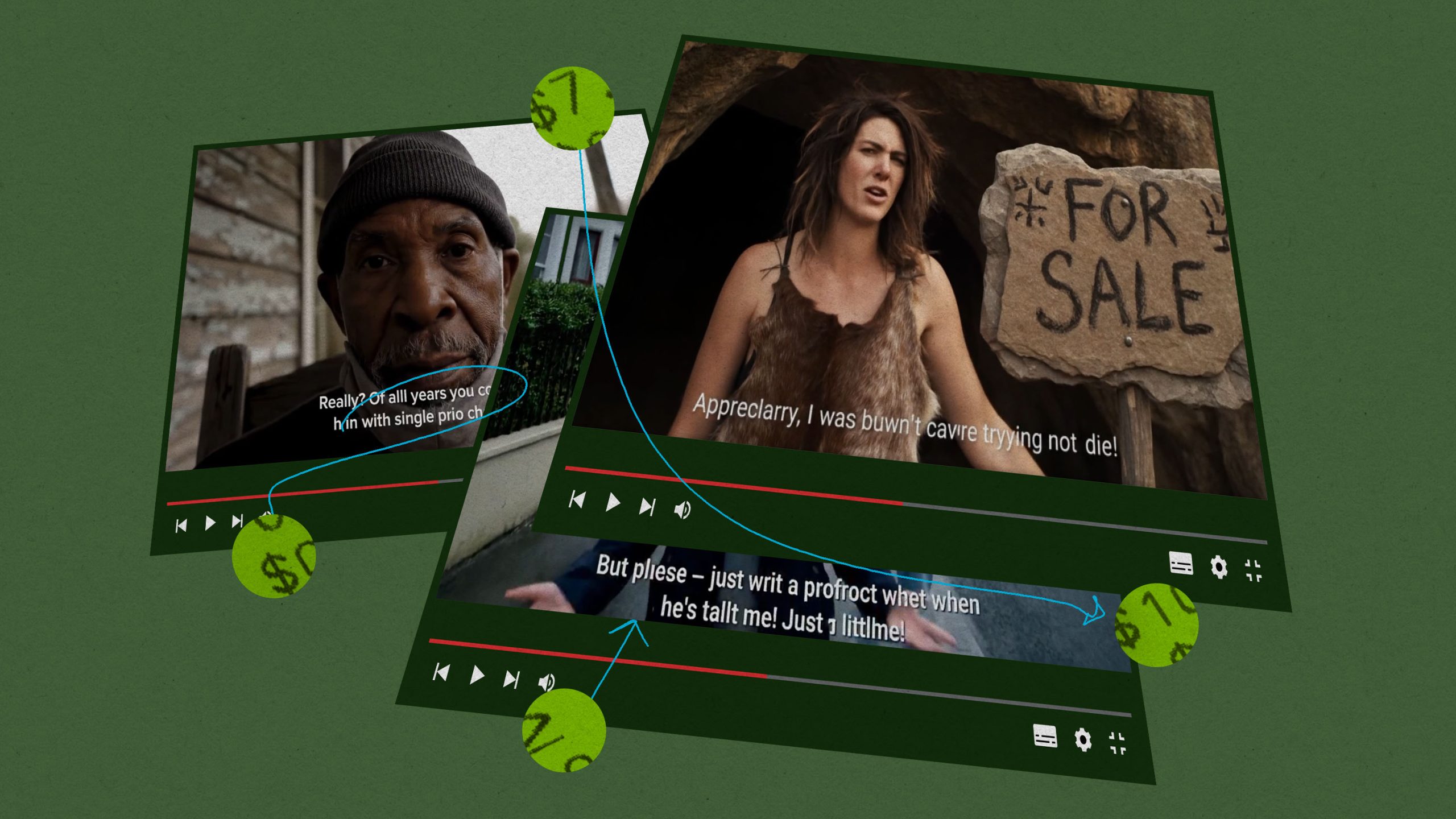
高品質で超高額、グーグル動画生成AI「Veo 3」で謎の字幕問題
グーグルが5月に発表した動画生成AI「Veo 3」で、ユーザーの指示を無視して意味不明な字幕を勝手に生成する問題が発生している。特に「売り」である、セリフを含むシーンの生成で頻繁に発生しているようだ。 by Rhiannon Williams2025.07.18
- この記事の3つのポイント
-
- グーグルが5月末に最新動画生成AIモデル「Veo 3」を発表した
- ユーザーたちは意味不明な字幕が勝手に追加される問題を発見した
- グーグルは修正版を開発したが1カ月後も問題は解決されていない
グーグルが5月末に最新の動画生成AIモデルを発表するやいなや、クリエイターたちはその性能を試そうと殺到した。前身モデルからわずか数カ月後にリリースされた「Veo(ベオ)3」は、初めて音声とセリフの生成を可能にし、8秒間の超リアルなクリップを繋ぎ合わせた広告、ASMR動画(編注:心地よい音やささやき声でリラックスを誘う動画)、想像上の映画予告編、ユーモラスな街頭インタビューなどが次々と制作される現象を引き起こした。アカデミー賞ノミネート監督のダレン・アロノフスキーらは、グーグル・ディープマインド(Google DeepMind)と共同で短編映画プロジェクトを立ち上げ、『アンセストラ(Ancestra)』という短編映画を制作した。グーグル・ディープマインドのデミス・ハサビスCEOは記者会見で、この飛躍的進歩を「動画生成の無声時代からの脱却」と表現した。
だが、ユーザーたちがすぐに気づいたのは、このツールがいくつかの点で期待通りに動作しないということだった。セリフを含むクリップを生成する際、Veo 3は、与えられたプロンプトでキャプションや字幕を追加しないよう明示的に求められている場合でも、しばしば意味不明で文字化けした字幕を追加してしまう。
それらを取り除くことは簡単ではなく、安価でもない。ユーザーはクリップを再生成する(これにはより多くの費用がかかる)か、外部の字幕除去ツールを使用するか、あるいは字幕を完全に取り除くために動画をトリミングするか、いずれかの手段に頼ることを余儀なくされている。
グーグルのグーグル・ラボ(Google Labs)/ジェミニ(Gemini)担当副社長であるジョシュ・ウッドワードは、6月9日にXに投稿し、意味不明なテキストを減らすための修正版を開発したと述べた。しかし1カ月以上経った後も、ユーザーはグーグル・ラボのディスコード・チャンネル(Discord channel)で依然として問題を報告し続けており、問題の修正がいかに困難であるかを示している。
Veo 3は前世代と同様に、月額249.99ドルからのグーグルのサブスクリプション・サービスの利用者向けに提供されている。8秒のクリップを生成するには、ユーザーは作成したいシーンを説明するテキスト・プロンプトをグーグルのAI映像制作ツール「Flow(フロー)」、Gemini、またはその他のグーグルのプラットフォームに入力する。動画の生成には最低20クレジットが必要であり、アカウントには2500クレジットあたり25ドルの費用でチャージできる。
広告クリエイティブ・ディレクターのモナ・ワイスは、ランダムなキャプションを除去するためにシーンを再生成することが高額になっていると話す。「セリフを含むシーンを作成する場合、出力の最大40%が意味不明の字幕となり、使い物になりません。気に入ったシーンを得ようとして何度も試すことでコストが嵩み、それでも使えないことがあります」。
無駄になったクレジットの返金を求め、ディスコードのチャンネルを通じてワイスがグーグル・ラボに問題を報告すると、同チームは彼女を同社の公式サポートに案内した。サポートはVeo 3の費用返金を提案したが、クレジットについては対象外だという。ワイスは提案を拒否した。これを受け入れることは、モデルへのアクセスを完全に失うことを意味したからだ。グーグル・ラボのディスコード・サポートチームは、字幕が音声によって引き起こされる可能性があるとユーザーには伝えており、問題を認識して修正に取り組んでいる、とする。
では、なぜVeo 3はこれらの字幕を追加することにこだわり、なぜこの問題を解決することがそれほど困難に見えるのだろうか。おそらく、モデルがどのような訓練データで訓練されたかに起因する。
グーグルは明らかにしていないが、Veo 3の訓練データにはユーチューブ(YouTube)の動画、ブログや ゲーミングチャンネルのクリップ、ティックトック(TikTok)の編集動画が含まれている可能性が高い。これらの多くには字幕が付いている。埋め込まれた字幕は、別のレイヤーに分けられたテキストフレームではなく、動画フレームの一部であるため、訓練の前に除去することは困難である。動画共有プラットフォームとAIを研究する米国クラーク大学のシュオ・ニウ助教授はこう説明する。
「テキスト動画生成モデルは、人間が作成した動画を模倣するコンテンツを生成するために強化学習を用いて訓練されており、そのような動画に字幕が含まれている場合、モデルは字幕を組み込むことで人間が生成したコンテンツとの類似性が向上することを『学習』する可能性があります」。
グーグルの広報担当者は、「当社は動画作成の改善に継続的に取り組んでおり、特にテキスト、自然に聞こえる音声、そして完璧に同期する音声に注力してます」と述べた。「不整合に気づいた場合は、ユーザーにプロンプトを再試行するとともに、フィードバック・ボタンでフィードバックすることを推奨しています」。
なぜモデルが「字幕なし」などの指示を無視するのだろうか? AIシステムを研究するニューヨーク州立大学ストーニーブルック校のトゥヒン・チャクラバルティ助教授は、否定的なプロンプト(生成AIモデルに何かをしないよう指示すること)は通常、肯定的なプロンプトよりも効果が低いと述べている。
この問題を解決するために、グーグルはVeo 3が訓練されたすべての動画の各フレームをチェックし、キャプション付きのフレームを削除するか再ラベル付けしてからモデルを再訓練する必要があるだろう。これは数週間を要する取り組みであると彼は述べている。
ドキュメンタリー制作者でMITオープン・ドキュメンタリー・ラボの芸術監督であるカテリーナ・チゼックは、この問題はグーグルが完全に準備が整う前に製品をリリースすることをいとわない姿勢を示していると捉えている。
「グーグルには勝利が必要でした。口の動きに同期した音声を生成するツールを最初に送り出す必要があったのです。字幕の問題を修正することよりも重要だったのでしょう」。
- 人気の記事ランキング
-
- Four nuclear reactors hit a big milestone in the US 米原子炉スタートアップ4社が臨界達成、原発新時代の幕開けか?
- Promotion Call for entries for Innovators Under 35 Japan 2026 「Innovators Under 35 Japan」2026年度候補者募集のお知らせ
- Anthropic found a hidden space where Claude puzzles over concepts LLMは何を考えているのか? アンソロピックが見つけた「隠れた領域」
- Interview with Prof. Keisuke Fujii 量子コンピューター、「設計思想」を問う段階へ——藤井啓祐教授に聞く
- Why worms (and microbes) are catching on as a manure pollution solution 汚染源を収益源へ カリフォルニア酪農が頼る 「ミミズの力」は本物か
- リアノン・ウィリアムズ [Rhiannon Williams]米国版 ニュース担当記者
- 米国版ニュースレター「ザ・ダウンロード(The Download)」の執筆を担当。MITテクノロジーレビュー入社以前は、英国「i (アイ)」紙のテクノロジー特派員、テレグラフ紙のテクノロジー担当記者を務めた。2021年には英国ジャーナリズム賞の最終選考に残ったほか、専門家としてBBCにも定期的に出演している。








