DALL-E、Imagen——進化する自動作画、AIは想像力を拡張するか
画像認識と自然言語処理を融合させたマルチモーダルなAI技術が広がりを見せている。オープンAIの「Image GPT」から「DALL-E2」、グーグルの「Imagen」まで、画像生成モデルの進化とその仕組みについてAI研究者の清水 亮氏が解説する。 by Ryo Shimizu2022.06.13
イーロン・マスクらが設立した人工知能(AI)研究機関、オープンAI(OpenAI)が昨年1月に発表した「DALL-E(ダリ―)」は、世界のAIコミュニティに大きな衝撃を与えた。それ以前のAIといえば、画像認識にしても、文章分類や生成にしても、あくまでも「画像は画像」、「文章は文章」として切り分けられていた。しかし、2020年頃から、「画像と文章」の関係性をより積極的に利用する、いわゆる「マルチモーダル」なAIが登場し始めた。
2020年にオープンAIが発表した「Image GPT(イメージGPT)」は、本来は文章を扱うモデルであるGPT(Generative Pre-trained Transformer)にいくつかのトリックを組み合わせて画像生成にも応用できるというものだ。画像を左上から右下へ向かって進む一種の「文章」とみなして、半分だけの画像を与えた後、その続きを生成させることに成功した。

オープンAIが2021年1月に発表したDALL-Eは、このマルチモーダルの考え方をさらに進めて、高解像度でなおかつ驚くほど独創的に見える画像の自動生成することに成功した。実際に筆者自身も実験で試してみると、確かに説得力のある画像が生成されることが確認できた。
オープンAIはこのすばらしい成果と論文を発表したものの、DALL-Eのモデルそのものは公開しなかった。このことがオープンソース・コミュニティを刺激し、世界中のAI研究者有志が集まり、独自にさまざまなアプローチで画像生成AIを作り始めた。
DALL-Eのオープンソース実装や、独自のデータセット、独自の学習済みモデルなどの開発や、DALL-Eの副産物として生まれた、画像と文章との相関関係を推定する「CLIP(クリップ)」というモデルが公開され、これによって世界中の研究者がCLIPを利用した画像生成モデルの開発に夢中になった。
初期に公開されたモデルで有名なものは「BigSleep(ビッグスリープ)」というモデルで、グーグルの開発した画像生成AIであるBigGAN(ビッグギャン)とCLIPを組み合わせてテキストから連想される画像を生成するものだった。


BigSleepは、非常に少ない手間で効果的なAIが構築できることの好例だ。AI開発で大変なのは主に学習だが、BigSleepではBigGANはグーグルが学習させ、CLIPはオープンAIが学習させたものを組み合わせただけだ。それだけでこれほど驚くような効果が生まれることがわかった。
この後、DALL-Eのクローンや、DALL-Eのクローンを作るためのデータセットなどが活発に開発され、現在そうした取り組みはLAION(ライオン)プロジェクトというコミュニティに発展している。LAIONプロジェクトでは、ネットで収集された4億枚に及ぶ画像とその説明文(キャプション)のセットが収集され、それを独自に学習させる方法まで細かく公開されている。ロシアでは、DALL-EとCLIPのロシア語版であるruDALL-E(ルダリ―)とruCLIP(ルクリップ)が公開され、中国でも同様の研究が発表されている。
オープンAIの基本方針はその名に反してかなりクローズドであり、その反動としてロシアや中国、そして国際的なオープンソース・コミュニティがよりオープンで自由な画像生成モデルを作り出そうとしている点は非常に興味深い。これら研究の中心はディスコード(Discord)にあり、LAIONプロジェクトのディスコードには毎日新しい理論や実装、実装により作られた作品が公開されている。
DALL-Eの原理と、DALL-E2とImagenへの進化
DALL-Eやその派生の原理は非常にシンプルだ。まずランダムな潜在ベクトルZをもとに、BigGANやVQGANなどの生成モデルが画像を生成する。生成された画像と与えられたキーフレーズの相関をCLIPが判定し、CLIPが感じた「違和感」を逆伝播させることでZを修正し、目的とする画像に近づけていく。
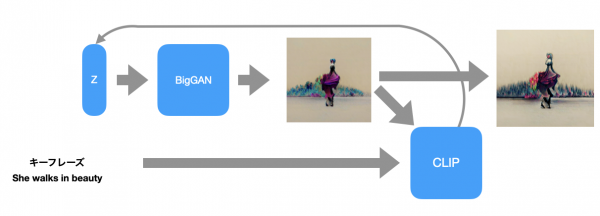
ポイントはCLIPの部分で、CLIPがすでに知っているもの(言葉)しか使えないという制約がある。例えば「自動車」や「鳥」といった言葉はCLIPは知っているが、「宮崎駿」などの言葉を与えると、宮崎駿のアニメーション作品ではなく、宮崎駿本人の肖像を描こうとしてしまう。
今年に入り、オープンAIはさらに高精度な画像生成を実現する「DALL-E(ダリ―)2」を発表した。DALL-E2による作例はあまりにも現実離れしているように見える。
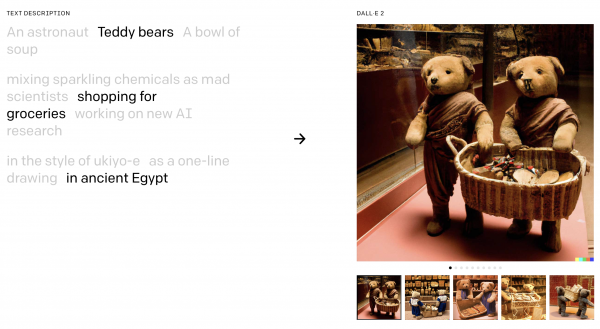

早速オープンソースコミュニティもDALL-E2を再現しようと取り組みが始まっている。こちらのColab(コラボ)では、DALL-E2のアルゴリズムを再現しようという試みが実施されている(編注:ColabはPythonで機械学習環境を作れるグーグルのサービス)。公式の例と同じく「古代エジプトの雑貨店で買い物をするテディベアたち(teddy bears shopping for groceries in ancient Egypt)」という文章を与えると、わずか数分でこんな画像が出力された。



確かにテディベアのようなものが雑貨店にいるような感じの画像になる。もっと長い時間学習させればもっとリアリテイのある画像になるのかもしれない。
グーグルの研究チームは新たに「Imagen(イメージェン)」という画像生成モデルを公開した。これは画像生成部分に分散モデル(Diffustion Model)を使用するもので、DALL-E2よりもシンプルな設計で、なおかつ高精細な画像を得ることができる。

グーグルもまたオープンAIと同じように、「公序良俗に反する画像を生成する恐れがあるため」という理由でImagenを公開していない。しかし、やはりオープンソースコミュニティではImagenを再現しようという試みはすでに始まっており、誰でも画像生成を試すことができる。ギットハブ(GitHub)の「cene555」というユーザーによるImagenの再現実装では、例えば「テディベアの写真」という文字列から下記のような画像を生成できる。

好奇心がAIを発展させ、AIが想像力を拡張する
画像生成するAIの進歩は今、非常に激しく、その原動力はお金よりもむしろ人間の持つ好奇心ではないかと思う。世界中のAI研究者たちが、論文も書かずにこれだけ熱心に再現実験に取り組むのは、「AIにどこまでできるか知りたい」という好奇心があってこそだろう。
これまで、分野を問わず研究者という生き物は年に数回ある学会に向けて論文発表することを目指して研究を進めてきた。ところがAI分野では、関連する学会が非常に多いため、学会発表を準備している間に他の研究者がより進んだ成果を発表してしまう可能性が非常に高い。
そのためAI関連の学会では査読が非常に難しくなっており、特にこうした既存の手法を再現するという試みは論文発表するのが難しい。しかし多くの人がボランティアとして、このようなオープンソース・コミュニティに参加し、またはスポンサーの支援を受けて大量の計算資源を導入して研究し、その成果を公開するのは、その根底にあくなき好奇心と単純に「AIで思い通りの絵が書けたらすごい」という子どものような純粋な気持ちがあるからではないかと思う。
AIが自由に絵を描く時代の到来は、人々を明らかに強化する。絵を描くのは非常に技術と才能のいる仕事であり、絵を上達するには何万時間も絵を描き続けなければならない。しかしすべての人が絵の上達だけに人生を使うわけにはいかない。もっと多くの人が、自分の考えを絵で表現できれば、もしくは、自分が何かを考えようとするときに、AIが自分の考えを絵にしてくれたら、それがもとで自分の発想そのものが大きく影響を受け変化し、想像力が拡張されることになる。こうした時代の到来が、もうおとぎ話ではなくなりつつあるのだ。
- 人気の記事ランキング
-
- It’s time to address the looming crisis in entry-level work. 「コーディングを学べ」もう通用せず、AIが若者の雇用を奪い始めた
- Promotion Call for entries for Innovators Under 35 Japan 2026 「Innovators Under 35 Japan」2026年度候補者募集のお知らせ
- China has approved the world’s first invasive brain-computer chip—here’s what’s next 中国、BCIを国家戦略に 世界初の商用化で イーロン・マスクにも先行
- Anthropic’s Code with Claude showed off coding’s future—whether you like it or not 「Claudeに任せてしまおう」 たった1年で激変したソフトウェア開発
- A reality check on the AI jobs hysteria 「ホワイトカラー消滅」 まだデータに兆候なし ——ただし若者に警戒信号
- 清水 亮 [Ryo Shimizu]日本版 寄稿者
- 1976年、長岡生まれ。プログラマーとして世界を放浪し、数々のソフトウェア開発を手掛ける人工知能研究者。東京大学情報学環客員研究員。主な著書に『よくわかる人工知能』(KADOKAWA)、『教養としてのプログラミング講座』(中央公論社)など。